Scraping NOAA tide prediction data for the 'Frisco Bay
Wrote a little Python (too) late last night to scrape and munge some tide station data from NOAA:
The result:
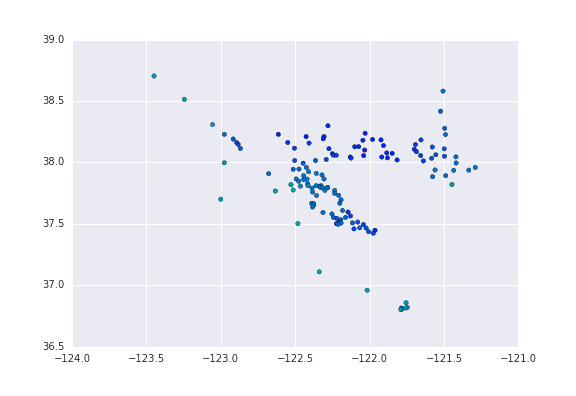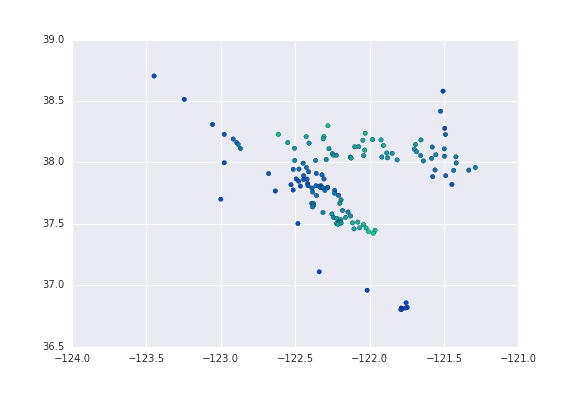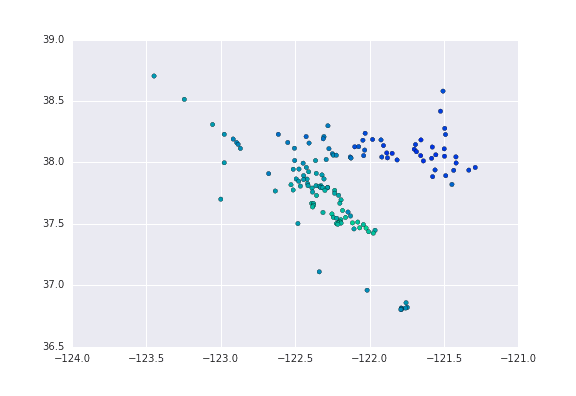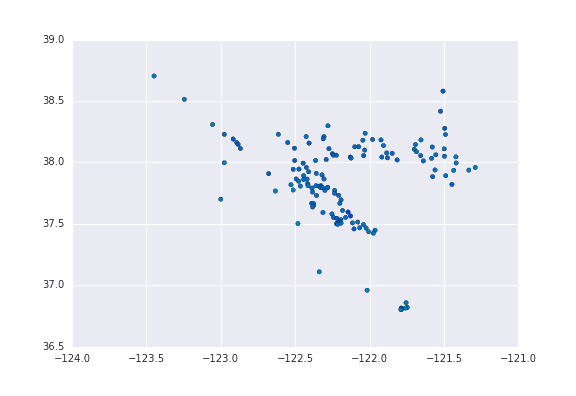
Wrote a little Python (too) late last night to scrape and munge some tide station data from NOAA:
The result: